2023-08-10
【Python × Selenium】GitHubのトレンドを取得するスクレイピングサンプルコード

エンジニアにはおなじみのサイトGitHub。
GitHubコミュニティで盛り上がっている、リアルタイムのトレンドを表示するページがあるのをご存知ですか?
今回は、GitHubの中で活発に更新されている技術やプロジェクトを、PythonとSeleniumでスクレイピングしました。
作成したコード
ページの遷移もなく、コードは至ってシンプルです。
トレンドリストを取得し、ランキング順にループでリストの内容を抽出しながら、タグ名やクラス名を基準に要素を配列に格納してゆきます。
- GitHubトレンドのページにアクセスし、上位10リポジトリを取得
- 取得した要素をループで展開しながら、要素内のテキスト情報を抽出し配列に格納
- 格納した情報はCSVファイル形式で保存
import time
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome import service as fs
SLEEP = 3
CSV_NAME = "trend.csv"
if __name__=="__main__":
chrome_service = fs.Service(executable_path='./chromedriver')
driver = webdriver.Chrome(service=chrome_service)
url = "https://github.com/trending"
driver.get(url)
time.sleep(SLEEP)
results = list()
items = driver.find_elements(By.CLASS_NAME, "Box-row")
for i in items[:10]:
item = dict()
item["title"]= i.find_element(By.TAG_NAME, "h2").text
item["url"] = i.find_element(By.TAG_NAME, "h2").find_element(By.TAG_NAME, "a").get_attribute("href")
lang_elements = i.find_elements(By.CSS_SELECTOR, ".d-inline-block.ml-0.mr-3")
item["lang"] = lang_elements[0].text if len(lang_elements) == 1 else None
item["total_star"] = i.find_elements(By.CSS_SELECTOR, ".Link--muted.d-inline-block.mr-3")[0].text
item["fork"] = i.find_elements(By.CSS_SELECTOR, ".Link--muted.d-inline-block.mr-3")[1].text
results.append(item)
pd.DataFrame(results).to_csv(CSV_NAME, index=False)
print(results)
driver.quit()
コードの動作を解説
順を追って確認しましょう。
ライブラリの読み込み
ライブラリやモジュールなどを読み込みます。
import time
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome import service as fs
timeライブラリを用いて、アクセス先サーバの負担を軽減するため意図的に処理を遅らせます。
pandasはデータ分析に特化したライブラリです。今回は取得したデータをCSV形式で保存するために使用します。
あとはselenium関係です。今回、serviceは必須ではありませんが、警告文を非表示にするため使用します。
変数の定義
コンパクトなコードなので、直に記述することもできますが、今後のコード拡張のためにも変数で管理しましょう。
SLEEP = 3
CSV_NAME = "trend.csv"
SLEEPで処理を中断する秒数を3秒に指定。
また、出力先CSVファイルのファイル名をtrend.csvに指定しています。
ドライバの読み込み
chrome_service = fs.Service(executable_path='./chromedriver')
driver = webdriver.Chrome(service=chrome_service)
ドライバを読み込むため、保存場所へのパスを指定します。
今回は実行ファイルと同階層に保存していることが前提としています。
データ取得先サイトへのアクセス
url = "https://github.com/trending"
driver.get(url)
time.sleep(SLEEP)
get()メソッドの引数にURLを取得し、サイトへアクセスできます。time.sleep(SLEEP)で処理を3秒間中断しています。もっとも、今回は処理内でのページ遷移がなく、アクセス先サーバの負担はないため不要だとは思いますが、慣用的な記述として使用しています。
ランキングを取得
results = list()
items = driver.find_elements(By.CLASS_NAME, "Box-row")
articleタグにクラス名Box-rowが振られリスト化されています。find_elements関数を使用して、クラス名Box-rowをもとにランキングを取得します。
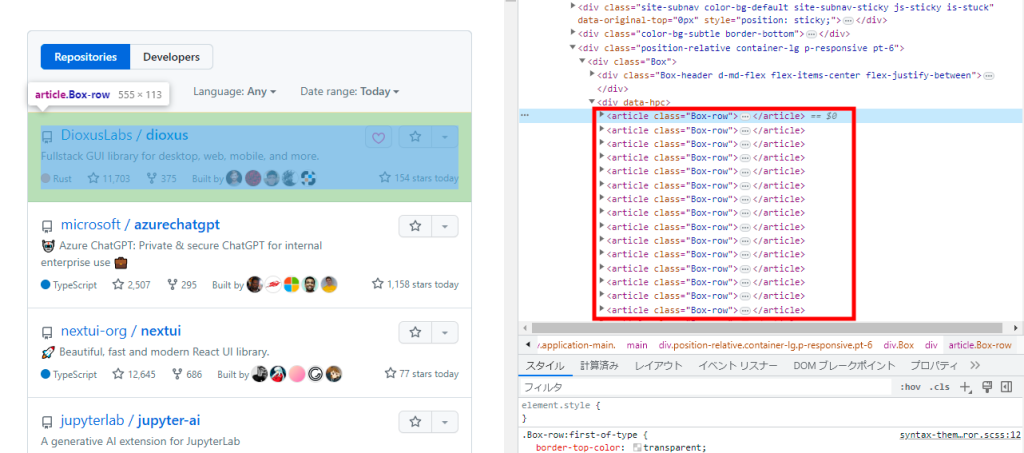
ランキングをループで展開し配列に格納
取得したランキングを格納していきます。
for i in items[:10]:
item = dict()
item["title"]= i.find_element(By.TAG_NAME, "h2").text
item["url"] = i.find_element(By.TAG_NAME, "h2").find_element(By.TAG_NAME, "a").get_attribute("href")
lang_elements = i.find_elements(By.CSS_SELECTOR, ".d-inline-block.ml-0.mr-3")
item["lang"] = lang_elements[0].text if len(lang_elements) == 1 else None
item["total_star"] = i.find_elements(By.CSS_SELECTOR, ".Link--muted.d-inline-block.mr-3")[0].text
item["fork"] = i.find_elements(By.CSS_SELECTOR, ".Link--muted.d-inline-block.mr-3")[1].text
results.append(item)
ループでプロジェクトごとに、辞書型データitemに格納。itemを配列resultに追加していきます。
プロジェクトごとのデータを取得する際には、find_element関数やfind_elements関数を用いて、タグ名やCSSセレクタを基準にテキスト情報を取得します。
ポイントはループする回数を指定することで、取得件数を1件目から10件に絞っている点です。
今回は詳細は省きますが、実はさまざまな指定が可能です。
for i in items[:10]: # :20とすれば20件取得可能
CSV形式でファイルに保存
pandasライブラリを用いて、ファイルを保存します。
配列をそのまま保存してくれます。
pd.DataFrame(results).to_csv(CSV_NAME, index=False)
print(results)
保存内容をコンソールに表示することもできます。
print(results)
CSV形式で保存できました。
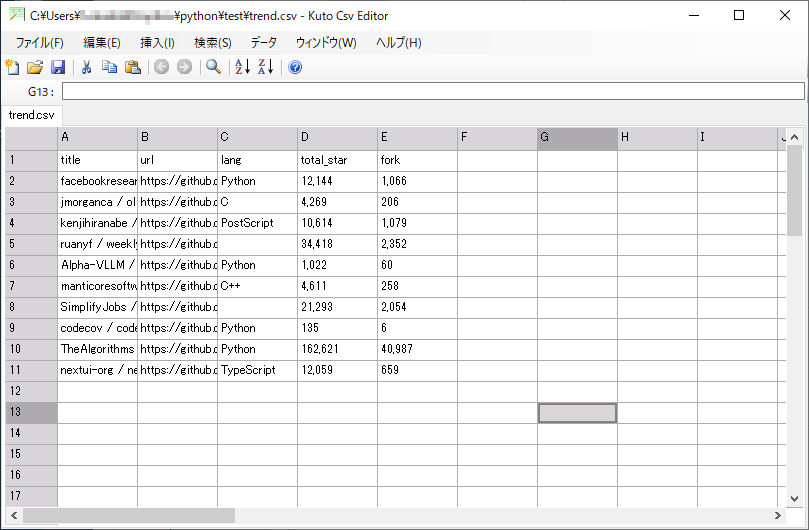
まとめ
今回はページ遷移を含まず、1ページの情報を取得するという内容でした。
サイトの特性や取得するデータによって、もっと複雑な処理が必要となります。
基本形のコードを確認するという意味では、非常にわかり易いコードだと思います。
print関数を用いるなど、コンソールで値を確認しながら進めると、より理解が深まると思います。