2023-08-02
【Python】Seleniumでスクレイピングを実行。サンプルコードを用いて解説

もはや珍しくもなくなったスクレイピング。
Python言語で行われることが主流で、利便性の高いSeleniumライブラリが用いられることが多いです。
わたしもスクレイピングを行う際はPython × Seleniumの環境を多用します。
今回はSeleniumライブラリを用いたスクレイピングを、基本的な最小コードサンプルでご紹介します。
ライブラリの設定からサイトへのアクセス、ブラウザの操作まで、簡単にではありますがサンプルコードをもとに解説します。実際には取得データの整形、保存などが重要となりますが、今回ご紹介するコードはSeleniumスクレイピングの基本形です。「基本のき」を確認しておきましょう。
スクレイピングとは
Webスクレイピングは、インターネット上のウェブサイトに存在する情報を、自動的に収集するための手法です。一般的に、目的となる特定サイトにアクセスしてHTMLコードを解析、必要なデータを抽出、保存するプロセスを指します。
例えば、購入を考えているある商品の価格を、複数のオンラインショップから収集することで、最安値情報や価格の値動きを追いかけ、希望条件にマッチした場合にお知らせをする、といったことが可能となります。
Webスクレイピングの一般的なステップ
- スクレイピングする対象のウェブサイトにアクセス
- ウェブサイトからHTMLコードを取得
- 取得したHTMLコードを解析し、必要なデータを見つけるために特定の要素やパターンを探す
- 解析した結果から必要なデータを抽出(通常はテキストや画像などの形式)
- 抽出したデータをデータベースに保存したり、他のアプリケーションで利用
Webスクレイピングは情報の取得という点で非常に便利ですが、利用する際に注意しなければならない事があります。取得先ウェブサイトの利用規約に違反しないようにすることや、取得先サイトのサーバーに負荷をかけすぎないように配慮することが重要です。ウェブサイトの運営者がWebスクレイピングを禁止、制限していないかどうか、事前に確認しましょう。
Seleniumライブラリについて
Selenium(セレニウム)は、ウェブブラウザを自動化するためのオープンソースのツールです。主にウェブアプリケーションのテストを自動化するために使用されますが、Webスクレイピングなどの用途でも利用されます。
Seleniumは人間が通常手動で行うようなウェブブラウザ上の操作を、自動的でコントロールすることができるツールです。例えば、特定のウェブページにアクセスしたり、ボタンをクリックしたり、フォームにテキストを入力したり、ページ内のテキストを読み取ったり、要素を検索したりといったことが可能です。
Webスクレイピングに関して言えば、必ずしもSeleniumを使用する必要はなく、他のライブラリを使用することで目的を果たすこともできます。しかし、Seleniumを使用することで、JavaScriptを用いて動的にロードするウェブページや、ユーザー操作が必要なページに対してもデータの取得が可能となり、データ取得の手法に幅が広がります。
今回はPython言語をベースに進めていますが、Seleniumは多くのプログラミング言語(Java、C#など)でサポートされています。
サンプルコードで実際にスクレイピングしてみる
では実際にコードを記述し、PythonでSeleniumを動かしていきましょう。
ちなみに、ブラウザはGoogleChromeで、下記の環境を前提にしています。
OS:Windows10
Python:3.11.1
Selenium: 4.1.0
Seleniumのインストール
pipコマンドでSeleniumをインストールします。
pip install selenium
driverのインストール
SeleniumはWebDriverを介してブラウザを操作する必要があるため、Seleniumを使うにはWebDriverのインストールが不可欠です。
使用できるブラウザはいくつかありますが、今回はGoogleChromeを使用します。WebDriverはブラウザ固有のものを準備する必要があります。
GoogleChromeのWebDriverダウンロード
https://chromedriver.chromium.org/downloads
サイトにアクセスし、インストールされているGoogleChromeに適合するバージョンのWebDriverをインストールします。
ブラウザが最新の状態であれば、最新のdriverをインストールすれば問題なく動作するかと思います。
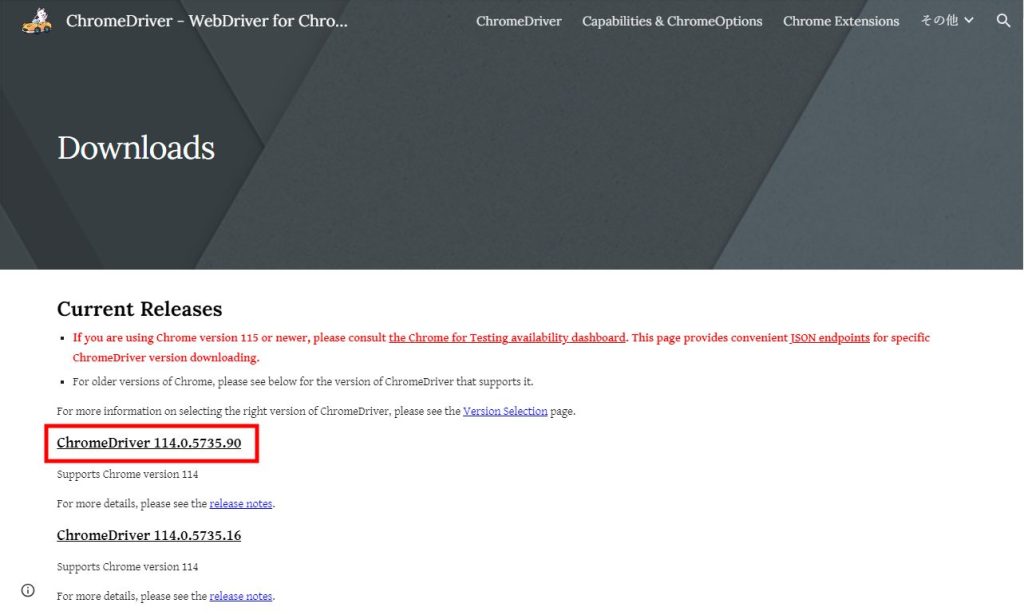
OSごとにdriverのダウンロードリンクが表示されています。
今回はwindows環境なので、chromedriver_win32.zipをクリックし.zipファイルをダウンロード、解凍します。
driverのファイル名はchromedriver.exeで、任意の場所に保存します。後ほどファイルの保存場所のパスが必要となります。
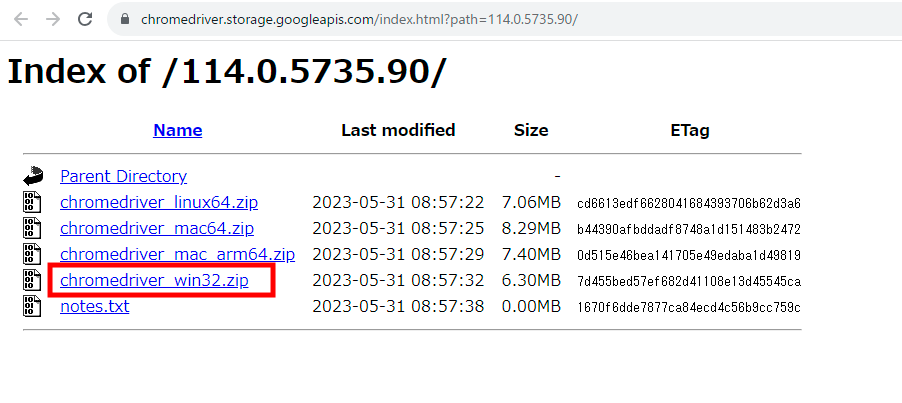
なお、現在使用しているGoogleChromeのバージョンは、
GoogleChromeの設定 > 設定 > Chromeについてから確認できます。
GoogleChromeを開いて、下記URLを打ち込んでも表示可能です。
chrome://settings/help
ブラウザを立ち上げる
実際にブラウザを立ち上げてみましょう。
先ほどインストールしたSeleniumモジュールを読み込みます。加えて、先ほどダウンロードしたchromedriverのパスを指定しdriverを起動します。
ファイル名はchromedriver.exeですが、.exeを省略しchromedriverと指定すれば問題ありません。
from selenium import webdriver #seleniumモジュールの読み込み
driver = webdriver.Chrome(r'C:\Users\xxxxx\Dropbox\python\selenium\chromedriver') # driverの読み込み
ブラウザが起動しました。
driverのパスは相対パスでも指定できます。下記は、実行するpythonファイルと同じ階層にdriverを設置した例です。
シンプルで見やすいですね…!
from selenium import webdriver
driver = webdriver.Chrome('chromedriver') # 相対パスでも指定できる
サイトにアクセスしてみる
サイトにアクセスしてみましょう。
driver.get()に引数でアクセスするサイトのURLを渡します。
下記サンプルコードはGoogleにアクセスします。
from selenium import webdriver
driver = webdriver.Chrome('chromedriver')
url = "https://www.google.com/" # アクセス先のurlを指定
driver.get(url) # サイトにアクセス
Googleのサイトが表示されました。
ページの要素を取得する
サイトにアクセスできましたので、ページ内の要素を操作していきましょう。
まず、ページ内のテキスト情報を取得し表示してみます。
ここでは「Googleについて」の情報を取得します。
Googleのトップページが開いた状態で、取得したい要素の上で右クリックします。
メニューが出てきますので「検証」をクリックし開発ツールを開きます。右側に(設定によっては左や下、別ページで表示されます)このページのソースコードが表示されます。
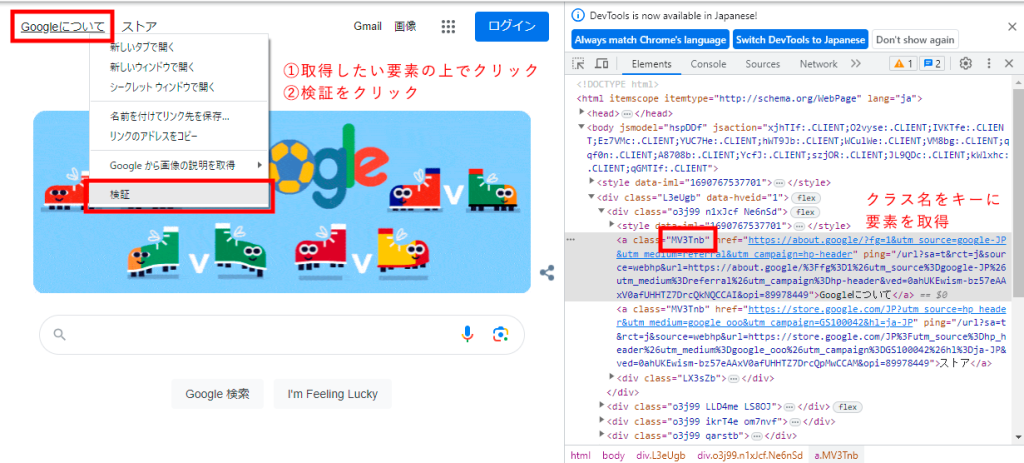
表示されたソースコードから、操作のヒントとなる情報を探りましょう。
今回はclass名MV3Tnbをキーに要素を取得します。
取得した要素は任意の変数aboutに格納し、print関数で出力します。
from selenium import webdriver
driver = webdriver.Chrome('chromedriver')
url = "https://www.google.com/"
driver.get(url)
about = driver.find_element_by_class_name('MV3Tnb') #class名を基に要素を取得
print(about.text) #タグの中身のテキストを取得
Pythonファイルを実行すると「Googleについて」と表示され、ページ内のテキストを取得、表示できていることが確認できます。

検索窓に検索キーワードを入力、検索結果の表示
はじめに検索窓を扱うために要素を取得します。
検索窓はtextareaタグで作成されていて、class名qが指定されています。このclass名qをキーに要素を取得します。
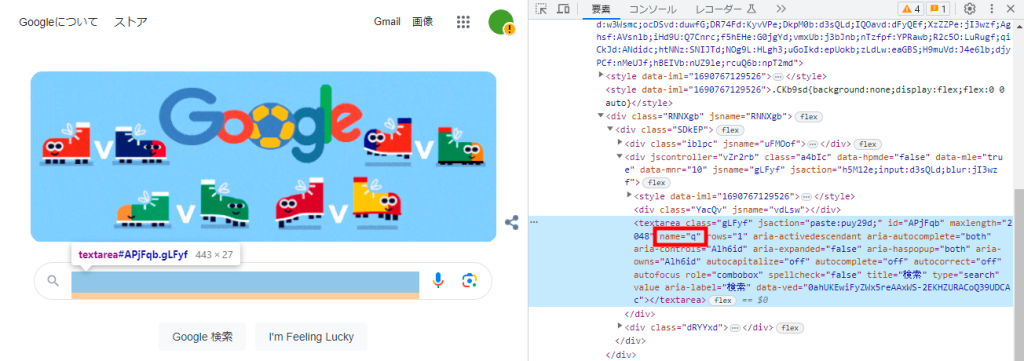
検索エリアtextareaタグの要素を取得します。
search_area = driver.find_element_by_name("q")
検索エリアに検索キーワードを入力。
search_area.send_keys("dailyhackon python")
検索ボタンを押下。
search_area.submit()
検索結果が表示されました。
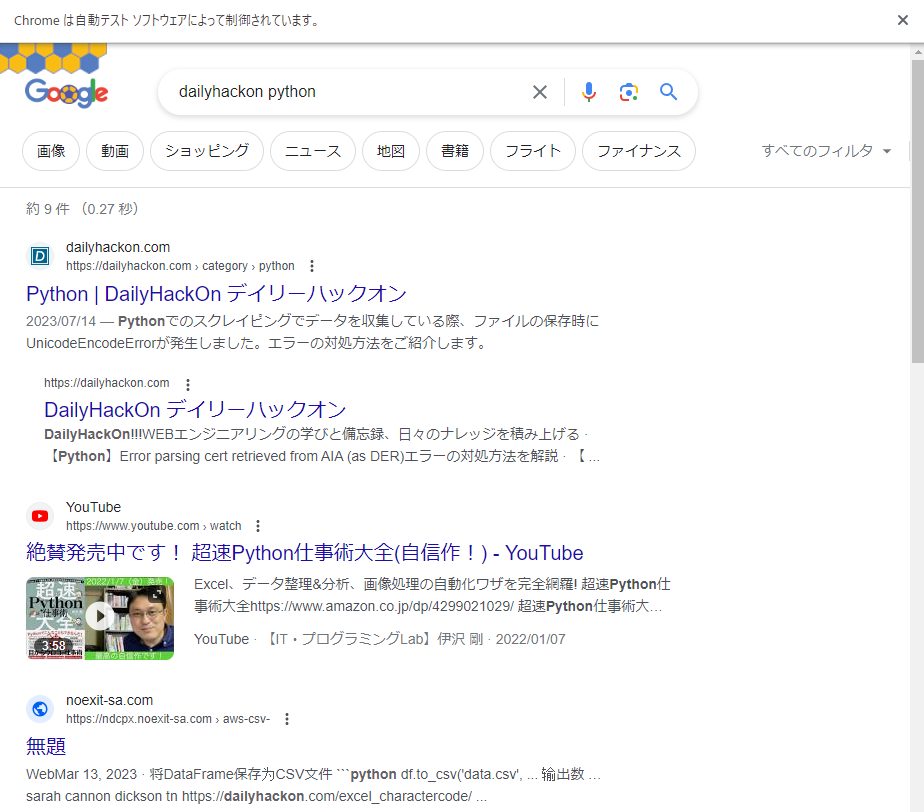
from selenium import webdriver
driver = webdriver.Chrome('chromedriver')
url = "https://www.google.com/"
driver.get(url)
search_area = driver.find_element_by_name("q") # 検索エリアtextareaタグの要素を取得
search_area.send_keys("dailyhackon python") # 検索エリアに検索キーワード「dailyhackon python」を入力
search_area.submit() # 検索ボタンの押下
自動でブラウザの動き、検索結果が表示される様子は面白いですね。
検索結果を取得、コンソールに表示する
検索結果の表示まで実装しました。
続いては、検索結果上位5件の見出しとURLを取得、表示してみましょう。
意図的に処理の遅延を発生させるため、timeモジュールの読み込み。
import time
これまでは要素を取得する際、find_element_by_*関数を使用していましたが、最新のSeleniumでは非推奨である旨の警告メッセージが表示されてしまいます。
Byモジュールを用いた記述に変換してみましょう。
DeprecationWarning: find_element_by_* commands are deprecated. Please use find_element() instead
search_area = driver.find_element_by_name("q")
Byモジュールの読み込み。
from selenium.webdriver.common.by import By
find_element_by_*関数をfind_element関数に変更します。
# search_area = driver.find_element_by_name("q") # 変更前
search_area = driver.find_element(By.NAME,"q") # 変更後
最終コードはこちらです。
検索結果をclass名をキーに取得。for文で要素(URL、タイトル)を指定回数を限度に配列にまとめ、最後にprint関数で出力しています。
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
SLEEP_TIME = 3
results = []
driver = webdriver.Chrome('chromedriver')
url = "https://www.google.com/"
driver.get(url)
# search_area = driver.find_element_by_name("q")
search_area = driver.find_element(By.NAME,"q")
search_area.send_keys("dailyhackon python")
search_area.submit()
time.sleep(SLEEP_TIME)
g_items = driver.find_elements(By.CLASS_NAME,'g')
for g in g_items:
result = {}
result['url'] = g.find_element(By.TAG_NAME,'a').get_attribute('href') # URLを取得
result['title'] = g.find_element(By.TAG_NAME,'h3').text # タイトルを取得
results.append(result) # resultを配列resultsに追加
if len(results) >= 5: # 件数を5件に限定、上限を越えるとループを抜ける
break
print(results) # 取得内容を出力
URLとタイトルをセットにデータを取得、表示できました。

まとめ
今回はコンソールに表示していますが、実際にスクレイピングをする際には、取得データをCSVファイルなどに保存したり、任意の形式に加工することが一般的です。もっと詳しい処理は別の記事でご紹介します。
このコードはSeleniumを用いたスクレイピングの最小レベルのサンプルだと思います。やりたいことに合わせて、コードを拡充していきましょう。
ちなみに、サイトの構造は日々変わります。class名や要素の変更に伴い、昨日は問題なく動作したコードでも、今日はclass名が存在せずエラーで取得できないという可能性もあります。サイトによっては、スクレイピング用ソースコードを日々見直さなければならない事、留意してください。